클러스터링은 input data들을 비슷하게 묶어 주는 것을 말하며 군집분석이라고도 한다.
아래의 그림에 샘플들이 색깔별로 나누어져 있는 것을 알 수 있다. 같은 그룹 속 샘플들은 특성이 비슷하다. 즉, 그룹간의 차이는 크게 그룹내의 차이는 작게 만드는 것이 군집을 잘 나누는 목적이라고 할 수 있다.
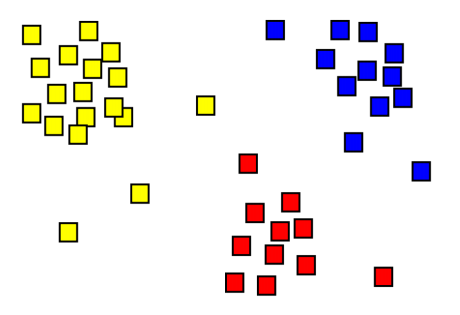
샘플 사이가 얼마나 가깝냐라고 하는 것은 distance measure를 활용한다. 그리고 그룹은 어떻게 나눌 것인가?에 대한 것은 clustering algorithm을 사용한다. clustering algorithm은 어떤 방식으로 그룹을 나눌 것인지에 대한 방법들이 존재한다.
이번 장에서 클러스터링에 대한 알고리즘은 K-means와 Hierarchical Clustering, 그리고 DBSCAN에 대해 알아본다.
K-means Clustering

objective function of clustering
�∈[1,2,...,�] 이고, ��는 �번째 cluster의 centroid이다. 여기서 �는 사용자가 지정하는 값이다. 간단히 말하면, 하나의 샘플이 포함된 �번째 cluster와의 거리가 최대한 가까운 cluster를 할당시켜주는 것이다. 아래의 경우의 수는 간단하게 샘플을 클러스터를 나눌 수 있는 모든 경우의 수를 나타낸다. 많은 계산이 필요하다는 것을 알 수 있다.
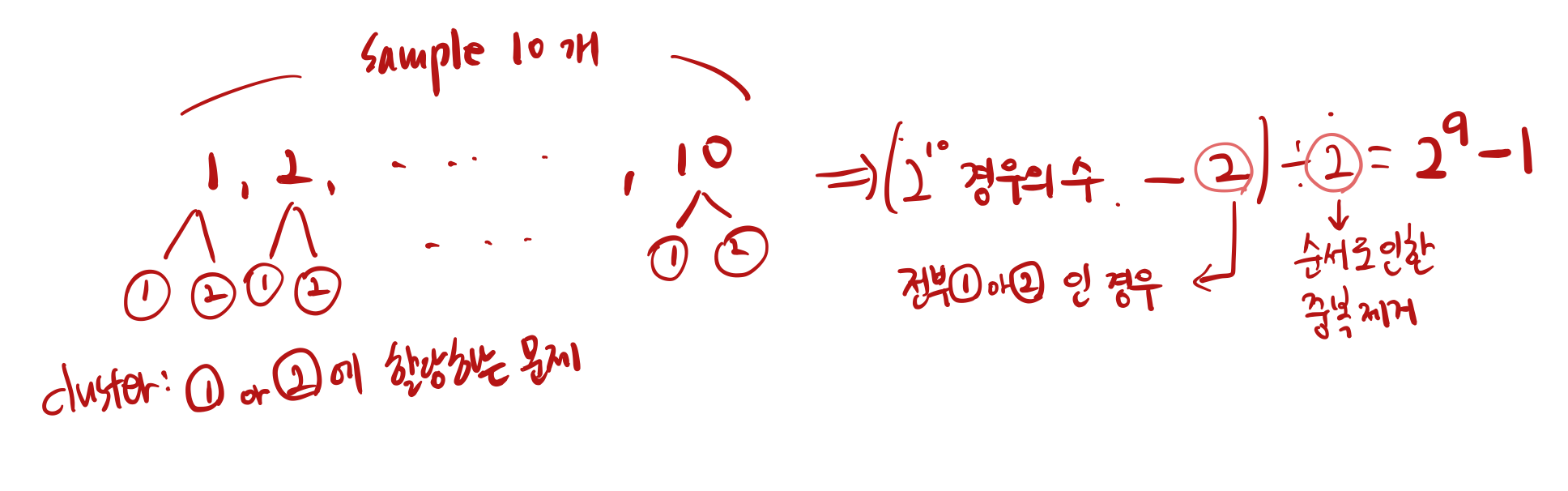
K-means 의 과정을 살펴보자.
1. � 개의 centroids(중심점)를 임의로 결정한다.
2. 각 샘플을 centroids들과의 거리를 구하여 가장 가까운 centroid에 샘플을 할당한다.
3. centroids를 업데이트한다. 이는 각 cluster에 평균을 활용한다.
4. 더이상 군집을 나눌 필요가 없다고 판단되면 과정을 종료한다. 일반적으로 이 판단 기준은 만족하기 쉽지 않아서 이전 거리와 변화된 거리가 threshold보다 작게 되면 종료하는 방법을 취한다.
아래의 그림은 과정을 도식화한 것이다. centroids를 3개 정하고, 거리를 구해서 clustering을 한다. 그리고 centroid를 평균을 활용하여 좀 더 중심으로 옮겨가게 된다. 빨간 부분은 샘플이 1개라서 평균이 해당 샘플 자체이므로 그 샘플이 위치한 곳으로 centroid를 옮기게 되고, 초록/파란 부분 역시 cluster 내의 샘플들의 평균 좌표로 centroid를 옮기게 된다.

예를 들어, (3,1), (2,2), (4,6)이 한 cluster에 있다면, 축별로 좌표들의 평균을 (3,2) 구하고, 이 위치로 centroids를 옮기게 된다.

clustering은 평균값을 사용하기 때문에 feature간의 scale 차이에 영향을 받기 때문에 표준점수 �=�−�� 또는 min-max 정규화 �=�−��������−���� 를 거쳐 0~1 사이의 값으로 만들어 주는 preprocessing과정을 사전에 진행하여 준다.
아래와 같은 데이터 샘플이 주어졌다고 가정해보자.

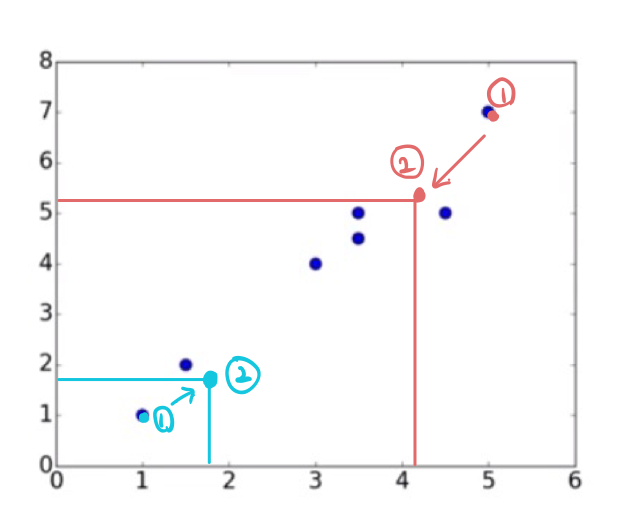
초기 initial centroid가 임의로 c1=(1,1), c2=(5,7) 두개의 class로 주어졌을 때. sample 중에 (1,1), (5,7)이 있지만, 엄연하게 임의로 선택된 initial centroid라고 가정하자.

위의 과정처럼, 모든 샘플을 centroid와 거리를 측정하고, 더 가까운 쪽의 centroid 로 clustering을 시켜주고, centroid에 모인 점들의 평균을 구해서 그들의 중심점을 centroid를 업데이트 함으로써 아래처럼 새로운 centroid를 생성한다.
s3 데이터는 흔치않지만 동일한 centroid와의 거리를 보이는데, 이는 과정이 거쳐가면서 자연스레 또 나누어 지게 된다. 아래의 결과처럼 s3은 class c2에 더 가까워진걸 볼 수 있다.
아래와 같이 centroid를 계속 업데이트 해주면서 중심점을 찾게 되고, 더이상 나아지는 정도가 별로 없거나, 지정한 반복횟수가 끝나면 최종 centroid 좌표를 출력하고, 각 데이터들은 clustering이 된 채로 output을 출력 된다.
Hierarchical Clustering
계층적 군집 알고리즘이라고 불리는 방법이다. 이름처럼 군집사이의 계층 구조를 학습하는 알고리즘이다. 예를 들어 동식물의 계통도를 보면 유사한 종(개별 샘플)끼리 하나의 속(계층구조)을 이루고, 속끼리 묶이면 과(더 큰 계층구조)가 되는 식으로 군집을 만든다.
계층적 군집 알고리즘은 크게 두가지로 나뉜다. Bottom up 방식의 Agglomerative와 Top down 방식의 Divisive로 나뉜다. 아래의 그림처럼 하나의 큰 클러스터에서 쪼개느냐, 아니면 가장 낮은 단위에서 클러스터를 구성해 나가느냐의 차이이다.
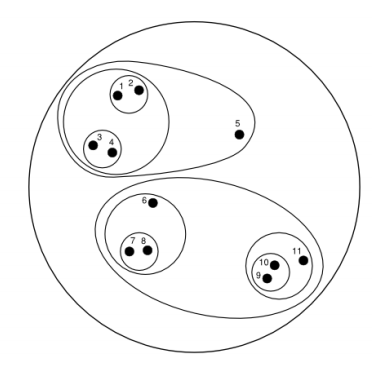
이렇게 계층을 나누기 위해서는 포함된 샘플이 다를 수 있는 클러스터 간의 유사도를 측정할 수 있어야 한다. 예를 들면 위의 1,2,3,4,5와 6,7,8,9,10,11을 처음에 나눌 때, 이 두 클러스터는 가지고 있는 샘플의 수가 다른데 이렇게 클러스터를 분리할 때 필요한 클러스터간 유사도(거리) 측정 지표가 필요하다. 이를 계산하기 위한 함수가 Linkage function 이라고 한다.
Linkage function

- Complete-linkage 는 각기 다른 cluster에 모든 점과 점 pairwise-distance를 구하고 그 중 최댓값을 활용한다.
- Single-linkage는 Complete-linkage와 같은 방식이되 최솟값을 활용한다.
아래의 그림을 보면 총 3 x 2개의 거리를 구하여 최댓/최솟값을 클러스터간 유사도 측정 지표로 활용한다. 클러스터를 묶는건 무조건 거리가 가장 가까운 것으로 선정하므로 Complete-linkage의 최댓값과 혼동하지 않도록 주의한다.
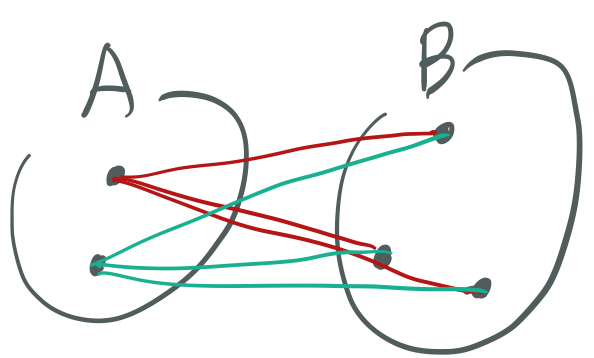
- Mean linkage는 위의 그림처럼 모든 거리를 구한 후, 총 거리의 개수 3x2로 나누어 평균값을 활용한다.
- Centroid linkage는 각 A, B의 좌표들의 평균 좌표(centroid)를 구하여 그 평균 좌표 사이의 거리를 활용한다.
- Ward linkage는 두 A,B를 합쳤을 때의 분산과 각각 분산과의 차이를 활용한다. 아래의 그림을 보면 각 A, B의 centroid로 부터 각 cluster내의 분산을 구할 수 있고, A, B 전체의 centroid로 부터 모든 샘플에 대해 분산을 구할 수 있다. 전체 분산이 클수록 두 클러터간의 거리가 멀다는 것을 의미한다.
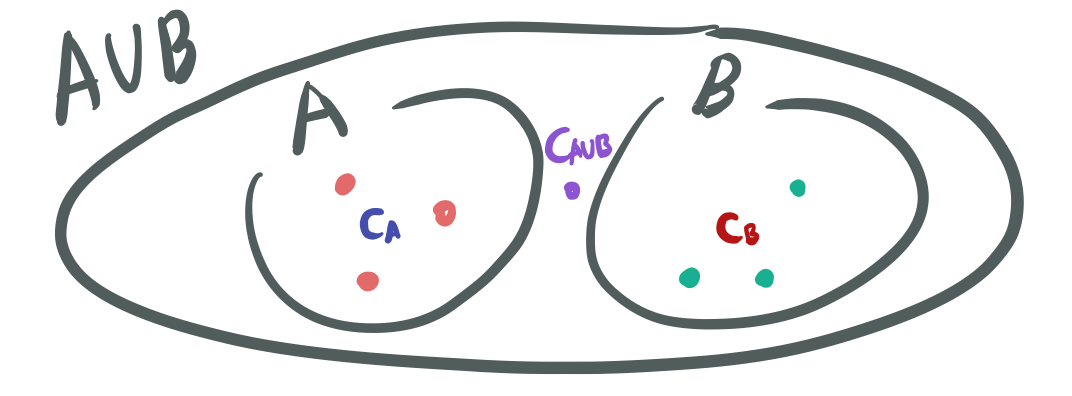
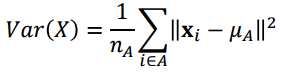
Ward linkage에서 분산 구하는 식.
Bottom up 방식으로 각 샘플이 개별 cluster인 것부터 시작해서 cluster를 만들어나가는 방법을 살펴보자. cluster간의 거리는 single linkage를 가지고 거리를 계산하면 아래의 순서대로 진행된다.
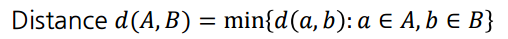
Single Linkage
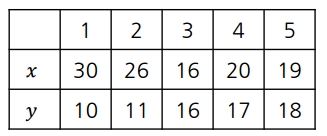
예시 5개의 샘플
1. 각 샘플이 처음에는 각자가 cluster니까 샘플 수와 클러스터수가 동일하니까 linkage이 뭐든지 거리가 짧은거를 선택하면 된다. 이에 C4, C5가 cluster가 먼저 되게 된다.
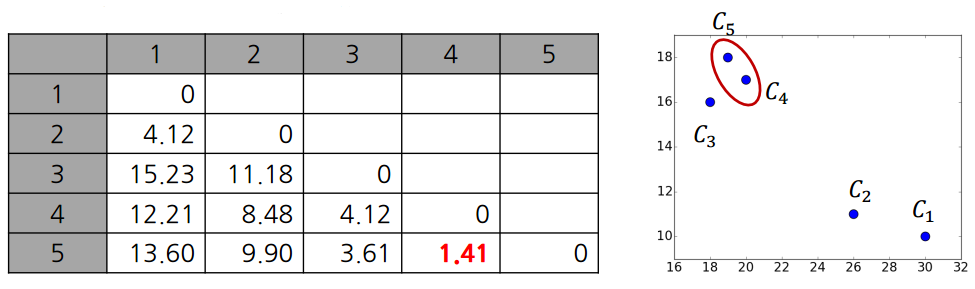
2. C4, C5가 묶인 cluster를 cluster C6이라고 새로 지정하면, 기존의 cluster C6과 cluster간 거리를 측정한 적이 없는 C1, C2, C3 과 linkage function을 이용해서 cluster 간의 거리를 구해준다.
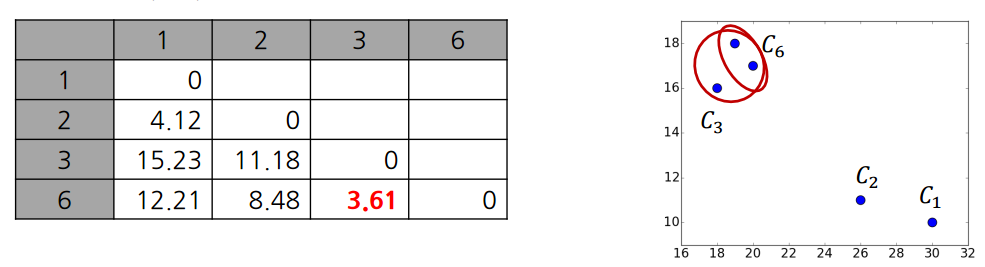
3. 이번에는 C6과 C3이 묶여 Cluster C7이 되었고, C1, C2도 이제 묶인 것을 볼 수 있다.

4.마지막으로는 두개의 cluster만 남아서 하나로 묶이게 된다. 이렇게 전체 샘플수가 n개이면 클러스터가 1개가 될 때 까지 n-1개의 clustering작업을 진행하게 된다.

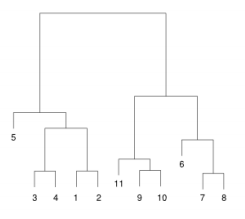
위의 작업은 아래의 Dendrogram으로 도식화 시켜서 볼 수 있다. 나타난 숫자는 clustering할 때, 둘 사이의 거리를 말한다. 이 값이 클수록 더 먼거리에 있는 cluster와 같이 clustering 된 것이라 생각하면 된다.
계층적 군집은 k-means처럼 임의로 centroid를 설정해서 하는게 아니기 때문에 원하는 지점에서 쪼갤 수 있는 장점이 있다. 아래 Dendrogram 을 만들고나면 빨간선으로 쪼갠 것처럼 원하는 지점에서 클러스터를 쪼갤 수 있다.
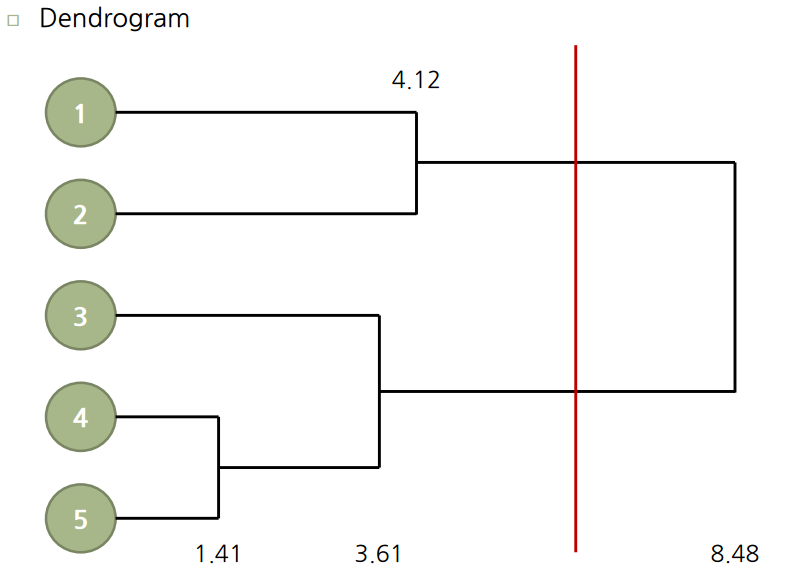
처음에 각각 1,2,3,4,5 cluster로 시작해서 위의 linkage function을 사용해서 cluster간 거리를 측정해가며 clustering을 해나간다. Dendrogram에서 빨간선처럼 cluster를 자르는 기준은 예를 들어 여기서는 clustering을 3번 해서 (1,2), (3,4,5) 까지 묶였다고 했을때, 한번 더 clustering을 하려니 cluster간 거리가 상당히 길다고 느껴져 잘라낸 것이다. 즉 4.12와 8.48의 차이는 이전보다 상당히 크기 때문에 위의 그림처럼 빨간선으로 적절히 잘라준 것이다.
DBSCAN (Density-based spatial clustering of applications with noise)
샘플들이 많이 밀집되어 있는 영역을 밀도가 낮은 지역을 가지고 구분짓는다. 앞 전의 방법과의 차이점은 density를 기반으로 한다는 점과 noise가 있다는 것이 가장 큰 차이점이다. 결과적으로 달라지는 것은 kmeans는 가까운 centroid로 할당이 되는데 이로 인해 선형으로 나누어지는 반면에, DBSCAN은 density 기반이라서 어떤 모양으로도 cluster가 구성이 될 수 있다.
DBSCAN의 경우에 샘플이 들어오면 다음과 같이 세가지 중 하나로 결정되게 된다.

- Core point : 높은 밀도를 가지는(중심에 있는 핵심.) 데이터.
- Reachable point: Core point는 아니지만 그 주변부에 속하는 데이터로 보통 이런 데이터들이 cluster의 경계를 구성한다.
- Outlier: core point도 reachable point도 아니고, 어느 cluster에도 속할 수 없는 데이터를 말한다. 앞전의 방법들은 outlier에 대해서도 무조건 clustering이 이루어 지지만, DBSCAN의 경우 outlier로 정의를 해줄 수 있다.
DBSCAN은 k-means의 �처럼 하이퍼 파라미터로 ������와 �를 가진다. ������는 데이터가 core point가 되기 위해 radius(�)안에 들어있는 최소 만족해야하는 이웃의 개수라고 생각하면 된다. 즉, 영역(radius)안의 밀도가 ������이상이 되면은 그 point는 core point라고 할 수 있다. 아래 그림에서는 ������를 4로 정의하였고 �은 radius 처럼 원 반경에 해당한다.
빨간 점은 반경안에 자기자신을 포함해서 ������가 4이상은 된다는 point로 core point에 해당한다. 그리고 Reachable point는 core point는 아니지만 core point들로 부터 한단계 한단계씩 거쳐 도달할 수 있는 포인트를 말한다.
Outlier는 어떤 점으로도 도달할 수 없는 포인트를 말한다.
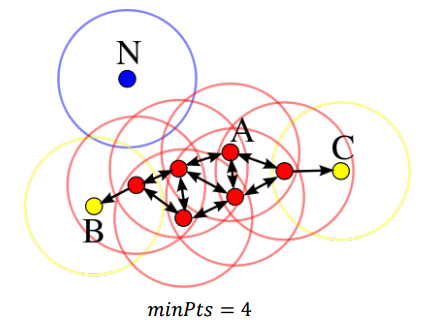
Density-reachablility 는 symmetric 한 관계가 아니다: core point가 아닌 점들은 반경 내에만 있으면, rechable 될 수 있다. core point에 지목을 받을 수 있는데, core point가 아닌 이상 다른 지점으로 나아갈 수는 없게 된다. 이는 k-means 같은 경우에 계속해서 rechable한 값들이 끝까지 cluster를 왓다갓다 하는 것을 방지하게 할 수 있다.
이에 Density-connectedness라는 개념이 나오는데, p, q 점이 density-connected되어 있다는 말은 동일한 core point �로 부터 rechable 하면 그 둘 p, q는 connected되어 있다는 말이다. 위의 그림을 보면 C와 B는 p,q가 되고 A가 �가 된다. B,C는 connected되어 있으니, reachability와 달리 symmetric하다고 할 수 있다.
Density-connectedness개념을 적용해서 cluster를 어떻게 하는지 알아보자.
하나의 클러스터를 이루기 위해선 특정 클러스터 안의 모든 점들은 전부 mutually density connected 되어 있어야 한다. mutually density connected는 완결성있게 되야한다는 뜻인데, core point로 다니면서 cluster 밖에 rechable point를 찾으면 같은 클러스터로 영입을 시키는 것이다.
정리하면 먼저 �과 ������를 만족하는 core point를 전부 찾는다. 그리고 반경내에 rechable point를 찾아나선다. 죽죽죽 cluster를 키워나가다가 더이상 영입할 점이 없으면, 아예 다른 corepoint로 넘어가서 죽죽죽 또다른 cluster를 만들게 된다.
장점.
- 숫자를 조절하는 것이 아니라 밀도를 조절할 수 있다. 특정 밀도나 구역을 정할 수 있는 2차원이나 눈으로 볼 수 있는 데이터에서 사용한다. 어떤 일이 많이 벌어지는 구역(밀도가 높은) 자체를 정의하고 싶은 경우에 DBSCAN이 앞의 방법보다 나은 대안이 될 수 있다.
- 클러스터 모양이 다양하게 나타나게 된다. 비선형적인 모양도 나온다.
단점.
- 둘 이상의 클러스터에서 reachable한 경계점(border points)은 둘 중 어느 한 클러스터로 영입될 수 있습니다.
- 거리 측정 방법에 의존한다는 점.
- 데이터에 따라서 영역별로 밀도가 많이 다를 수 있다. sparse한 cluster혹은 굉장히 dense한 cluster일 수도 있다. 즉, ������와 �를 모든 클러스터에 대해 적절히 선택해주어야한다. 밀도를 고려해서 영역별로 알아서 조절할 수 있게 하는 연구들이 있음.
- 데이터, scale에 대해서 잘 모르는 상태(볼 수 없는 상태)일 수록 hyperparameter 튜닝에 애를 먹을 수 있다.
Evaluation Measure
비지도 학습인 만큼 학습에 대한 명시적인 정답이 존재하지 않는다. 그래서 어떻게 성능을 측정할지가 이슈가 된다.
클러스터링 목적에 맞게끔 잘 달성했느냐를 기준으로 측정을 할 수 있다. 클러스터링의 목적은 같은 클러스터내의 점들은 가깝고, 클러스터간의 거리는 멀고, 그러한 목적에 부합하게끔 잘 나누어 졌는지를 기준으로 성능을 측정해본다.
첫번째 지표는 Inertia(Within-cluster sum of squared error) 지표이다. 각 클러스터 내에서 샘플들과 해당 centroid와의 거리를 측정해서 작을 수록 좋다. 특정 클러스터 내의 SSE를 합하고 이것이 작을 수록 클러스터링이 잘 됐다고 할 수 있는 지표이다.
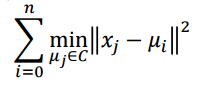
Inertia
두번째 지표는 Silhouette Coefficient이다. �(�)는 개별 측정 i번째 샘플을 말하며, �(�)는 해당 샘플이 포함된 클러스터내의 모든 다른 샘플들과의 거리 평균이고, �(�)는 해당 샘플이 포함된 클러스터와 가장 가까이에 있는 다른 클러스터에 존재하는 모든 샘플들과의 거리 평균이다. 전체 클러스터링에 대한 성능은 �(�)의 평균으로 구한다.
�(�)가 음수가 나오면 자기가 속한 클러스터와의 거리보다 다른 클러스터와의 거리가 더 가깝다는 것이므로 문제가 좀 있는 포인트라고 할 수 있다.
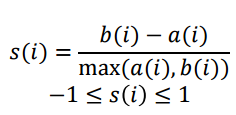
Silhouette Coefficient
세번째 클러스터링 성능 측정 지표는 Homogeneity, Completeness이다. 특이하게 이 지표는 LABEL 정보를 활용한다. 이 지표는 새롭게 클러스터링 방법을 연구하는 사람이 기존의 방법과 비교를 하기 위해서 만들어진 지표라고 생각하면 된다. 벤치마크 데이터셋(classification)을 가져와서 자신들의 알고리즘의 성능이 더 좋다는 것을 보여주기 위한 용도로 사용한다.
H(C)라 하는 것은 의사결정나무에서 했던 앤트로피 값이다. C라는 것은 실제 class label을 말하고 K는 clustering 한 class label을 말한다. 여기서 K안에 있는 cluster 개수는 달라도 상관 없다.
H(C|K)는 원래 루트노드에서 각 클러스터 별로 자식 노드를 만들었다고 생각하면 된다. 그 자식 노드 레벨에서의 엔트로피 값이 된다. 개별 클러스터 안에서 class의 비율을 계산해서 엔트로피를 계산한다.
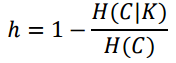
Homogeneity
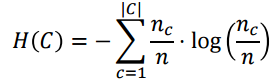
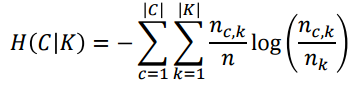
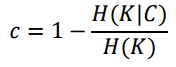
Completeness
이러한 지표가 가지는 의미에 대해 알아보자. 같은 class의 샘플이라하면 서로 유사할 것이다라는 가정하에 진행을 하는 것이다. homogeneity는 같은 클러스터 내에 하나의 class만 존재한다고 하면, 그 자식 노드에서의 값은 0이 되게 된다. 반대로 여러개의 class가 분포하고 있다면, 엔트로피값은 증가를 하게 된다. 그래서 h 값의 경우에는 모든 클러스터마다 하나의 class만 존재하는 것이 이상적이라 한다. 그러면 h = 1이 되니.
그다음 지표는 Adjusted Rand Index(ARI) 이다. 수식은 아래와 같다.
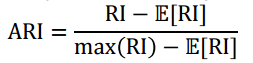
Adjusted Rand Index
먼저 Raw Rand index(��)를 먼저 보면 ��=�+��2� 이다 (�2�는 데이터 셋내에 모든 가능한 pairwise들이다.). �는 전체 데이터를 pairwise하고, 같은 class에 있으면서 같은 cluster에 속해있던 쌍의 개수를 말하며, �는 다른 class에 속하면서 cluster도 다르게 할당된 쌍의 개수를 말한다. 둘 다 높으면 좋은 것이다. 같은 class면 같은 cluster이면 좋은거고, 다른 class면 다른 cluster에 할당되야 좋은 것이다는 말이다. 즉 ��는 모든 쌍 중에서 좋은 쌍의 비중을 말한다.
RI같은 경우는 cluster의 개수에 따라서 무작위로 랜덤하게 k개의 cluster로 할당하는거에 비해서 얼마나 좋은지를 측정할 필요성에 대한 지표이다. RI만 보면 cluster개수에 따라 좋은건지 상대적으로 구분하기 힘들어서 ARI를 사용한다.
ARI는 무작위로 하는 것에 비해서 RI가 얼마나 더 좋냐를 보는 건데, 정규화는 시켜주고, 그 값을 계산하는 방법은 아래Contingency table을 사용한다.

Contingency table
K는 클러스터고 s개로 나누어져있고, C는 class이고 r개로 나누어져 있다. 각 구성에 따라서 cluster에 속하고 class에 속하는 그런 경우의 수들을 채울 수 있다. 계산 과정은 어렵지 않음..
이러한 지표들의 단점은 label 값을 사용한다는 것이다. 애초에 목적이 새로운 알고리즘의 성능비교를 위한 것이기 때문이기 때문에 일반적일 때는 사용하지 않는다.