거대언어모델(Large Language Model, LLM)

대용량의 인간 언어를 이해하고 생성할 수 있도록 훈련된 인공지능(AI) 모델이다. 딥러닝 알고리즘과 통계 모델링을 바탕으로 자연어처리 작업에 활용된다. 주어진 언어 범위 내에서 정해진 패턴이나 구조, 관계를 학습하는 기존 언어모델과 달리 대규모 언어 데이터를 학습해 문장 구조 문법, 의미 등을 파악하고 자연스러운 대화 형태로 상호작용이 가능하다.
국내에서는 대규모언어모델이라고도 불린다. 콘텐츠 패턴을 학습해 추론 결과로 새로운 콘텐츠를 만드는 생성형 AI의 핵심 기본 기술로 손꼽힌다. 오픈AI에서 개발한 '챗GPT'와 구글이 채팅 기반 AI 도구 바드에 적용한 'PaLM', 메타의 'LLaMa' 등이 대표적 사례다.
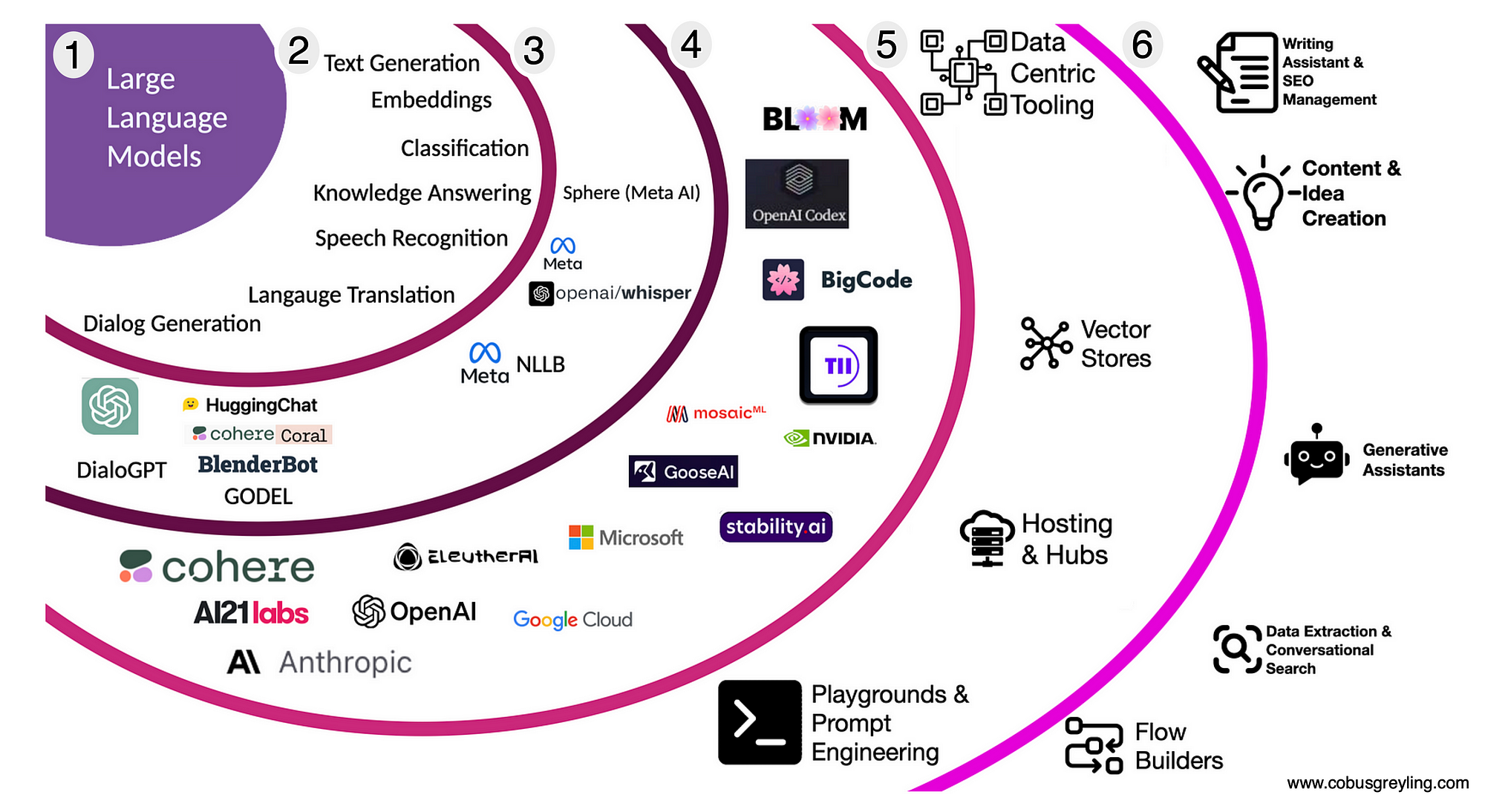
대형 언어 모델(Large language model, LLM) 또는 거대 언어 모델은 수많은 파라미터(보통 수십억 웨이트 이상)를 보유한 인공 신경망으로 구성되는 언어 모델이다. 자기 지도 학습이나 반자기지도학습을 사용하여 레이블링되지 않은 상당한 양의 텍스트로 훈련된다.[1] LLM은 2018년 즈음에 모습을 드러냈으며 다양한 작업을 위해 수행된다. 이전의 특정 작업의 특수한 지도 학습 모델의 훈련 패러다임에서 벗어나 자연어 처리 연구로 초점이 옮겨졌다.
대규모 언어 모델(LLM) 은 AI 챗봇 기술을 가능하게 하는 요소이며 많은 화제를 불러일으키고 있는 주제 중 하나다. 대규모 언어 모델(LLM)의 작동 방식은 크게 3가지로 나뉘고 있다. 토큰화, 트랜스포머 모델, 프롬프트 등. 토큰화는 자연어 처리의 일부로 일반 인간 언어를 저수준 기계 시스템(LLMS)가 이해할 수 있는 시퀀스로 변환하는 작업을 말하며 여기에는 섹션에 숫자 값을 할당하고 빠른 분석을 위해 인코딩하는 작업이 수반된다. 이는 음성학의 AI 버전과 같으며 토큰화의 목적은 인공지능이 문장의 구조를 예측하기 위한 학습 가이드 또는 공식과 같은 컨텍스트 백터를 생성하는 것이 목적. 언어를 더 많이 연구하고 문장이 어떻게 구성되는지 이해할수록 특정 유형의 문장에서 다음 언어에 대한 예측이 더 정확 해진다. 이로 인해 온라인에서 사람들이 사용하는 다양한 커뮤니케이션 스타일을 재현하는 모델을 개발할 수 있다.
트랜스포머 모델은 순차적 데이터를 검사하여 어떤 단어가 서로 뒤따를 가능성이 높은지 관련 패턴을 식별하는 신경망의 일종으로 각각 다른 분석을 수행하여 어떤 단어가 호환되는지 결정하는 계층으로 구성된다. 이러한 모델은 언어를 학습하지 않고 알고리즘에 의존하여 사람이 쓴 단어를 이해하고 예를들어, 힙스터 커피 블로그를 제공함으로써 커피에 대한 표준 글을 작성하도록 학습 시킨다. 이 트랜스포머 모델이 대규모 언어 모델 LLM 언어 생성의 기초.
프롬프트는 개발자가 정보를 분석하고 토큰화하기 위해 대규모 언어 모델 LLM에 제공하는 정보로 프롬프트는 기본적으로 다양한 사용 사례에서 LLM에 도움이 되는 학습 데이터 입니다. 더 정확한 프롬프트를 받을수록 LLM은 다음 단어를 더 잘 예측하고 정확한 문장을 구성할 수 있습니다. 따라서 딥러닝 AI의 적절한 학습을 위해서는 적절한 프롬프트를 선택하는 것이 중요하다.
대형 언어 모델 목록
| BERT | 2018년 | 구글 | 340 million[2] | 3.3 billion words[2] | Apache 2.0[3] |
| XLNet | 2019년 | ~340 million[4] | 33 billion words | ||
| GPT-2 | 2019년 | OpenAI | 1.5 billion[5] | 40GB[6] (~10 billion tokens)[7] | MIT[8] |
| GPT-3 | 2020년 | OpenAI | 175 billion[9] | 300 billion tokens[7] | 공개 웹 API |
| GPT-Neo | 2021년 3월 | EleutherAI | 2.7 billion[10] | 825 GiB[11] | MIT[12] |
| GPT-J | 2021년 6월 | EleutherAI | 6 billion[13] | 825 GiB[11] | Apache 2.0 |
| Megatron-Turing NLG | 2021년 10월[14] | Microsoft and Nvidia | 530 billion[15] | 338.6 billion tokens[15] | 제한된 웹 접근 |
| Ernie 3.0 Titan | 2021년 12월 | Baidu | 260 billion[16] | 4 Tb | 사유(Proprietary) |
| Claude[17] | 2021년 12월 | Anthropic | 52 billion[18] | 400 billion tokens[18] | 클로즈드 베타 |
| GLaM (Generalist Language Model) | 2021년 12월 | 1.2 trillion[19] | 1.6 trillion tokens[19] | 사유(Proprietary) | |
| Gopher | 2021년 12월 | DeepMind | 280 billion[20] | 300 billion tokens[21] | 사유(Proprietary) |
| LaMDA (Language Models for Dialog Applications) | 2022년 1월 | 137 billion[22] | 1.56T words,[22] 168 billion tokens[21] | 사유(Proprietary) | |
| GPT-NeoX | 2022년 2월 | EleutherAI | 20 billion[23] | 825 GiB[11] | Apache 2.0 |
| Chinchilla | 2022년 3월 | DeepMind | 70 billion[24] | 1.4 trillion tokens[24][21] | 사유(Proprietary) |
| PaLM (Pathways Language Model) | 2022년 4월 | 540 billion[25] | 768 billion tokens[24] | 사유(Proprietary) | |
| OPT (Open Pretrained Transformer) | 2022년 5월 | Meta | 175 billion[26] | 180 billion tokens[27] | 비상업적 연구[d] |
| YaLM 100B | 2022년 6월 | Yandex | 100 billion[28] | 1.7TB[28] | Apache 2.0 |
| Minerva | 2022년 6월 | 540 billion[29] | 38.5B tokens from webpages filtered for mathematical content and from papers submitted to the arXiv preprint server[29] | 사유(Proprietary) | |
| BLOOM | 2022년 7월 | Large collaboration led by Hugging Face | 175 billion[30] | 350 billion tokens (1.6TB)[31] | Responsible AI |
| Galactica | 2022년 11월 | Meta | 120 billion | 106 billion tokens[32] | CC-BY-NC-4.0 |
| AlexaTM (Teacher Models) | 2022년 11월 | Amazon | 20 billion[33] | 1.3 trillion[34] | 공개 웹 API[35] |
| LLaMA (Large Language Model Meta AI) | 2023년 2월 | Meta | 65 billion[36] | 1.4 trillion[36] | 비상업적 연구[e] |
| GPT-4 | 2023년 3월 | OpenAI | 정확한 수치 알 수 없음. 대략 1 trillion [f] | 알 수 없음 | 공개 웹 API |
| Cerebras-GPT | 2023년 3월 | Cerebras | 13 billion[38] | Apache 2.0 | |
| Falcon | 2023년 3월 | Technology Innovation Institute | 40 billion[39] | 1 Trillion tokens (1TB)[39] | 사유(Proprietary) |
| BloombergGPT | 2023년 3월 | Bloomberg L.P. | 50 billion | 363 billion token dataset based on Bloomberg's data sources, plus 345 billion tokens from general purpose datasets[40] | 사유(Proprietary) |
| PanGu-Σ | 2023년 3월 | Huawei | 1.085 trillion | 329 billion tokens[41] | 사유(Proprietary) |
| OpenAssistant[42] | 2023년 3월 | LAION | 17 billion | 1.5 trillion tokens | Apache 2.0 |
| PaLM 2 (Pathways Language Model 2) | 2023년 5월 | 340 billion[43] | 3.6 trillion tokens[43] | 사유(Proprietary) |